Transforming Product Data into Intelligence with Context Engineering
Every week, raw vendor feeds arrive in mismatched formats, forcing teams to spend hours reconciling data before any SKU can safely reach the catalog.
Messy product data is more than an operational nuisance; it erodes revenue, frustrates customers, and diverts skilled talent to never ending cleanup. Inadequate data quality costs the average enterprise about thirteen million dollars each year, and knowledge workers lose up to half of their time searching for and correcting errors rather than creating value. Poor catalog content depresses add-to-cart rates and search visibility across ecommerce channels, while B2B buyers now enter formal evaluations with only a handful of vendors on their shortlist. In an environment where attention is scarce, every data flaw becomes a competitive liability.
The hidden tax of bad product data
Our customer engagements repeatedly reveal common patterns: nearly half of product catalog records contain outright errors, and the majority lack the precision and detail required for effective merchandising and content creation. The fallout is visible across the funnel: marketing campaigns convert poorly, support tickets rise, and product managers spend a disproportionate share of their week fixing spreadsheets instead of studying the market.
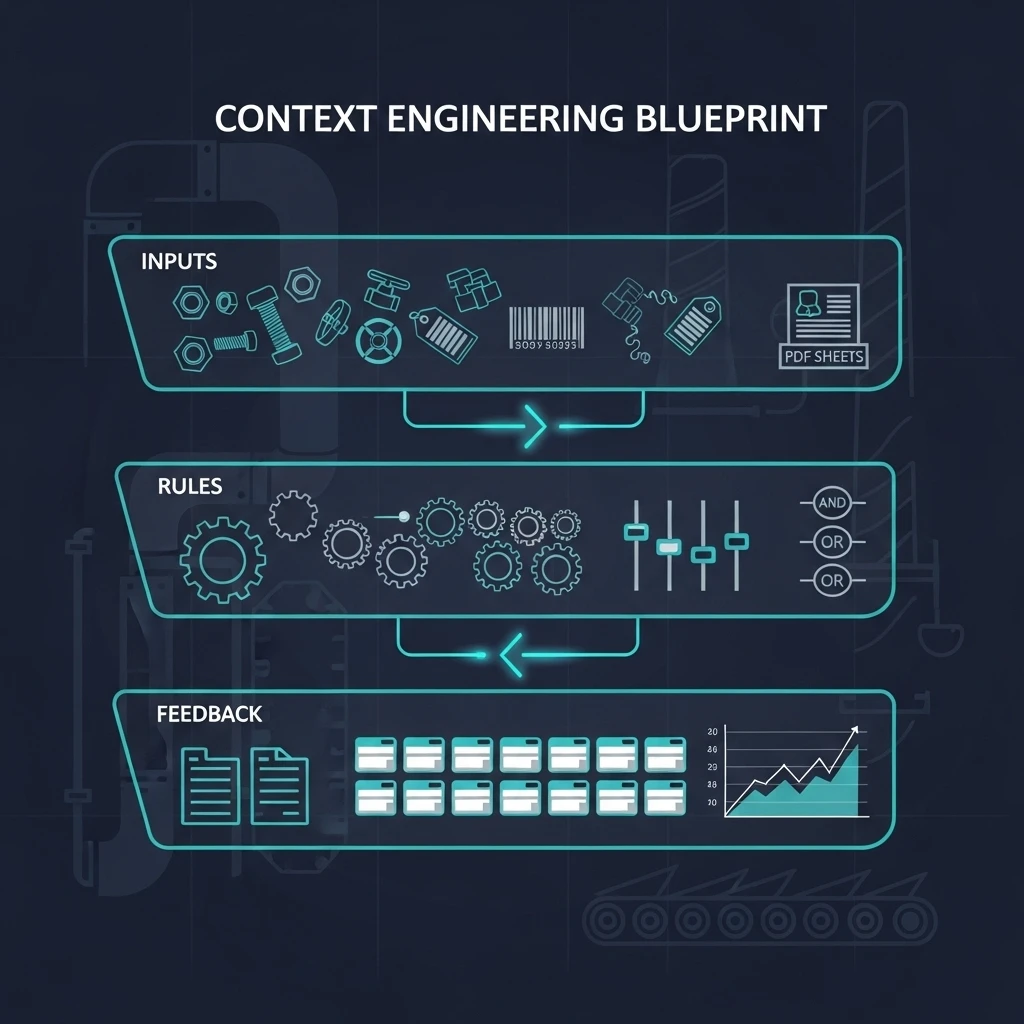
Context engineering as the catalyst for AI success
Traditional cleanup methods cannot keep pace with today's volume and variability of product data. Modern AI agents powered by large language models can classify, enrich, and correct records at a speed no human team can match, but only when they operate with the right context. Without that guidance, the very model that could rescue a catalog will simply automate mistakes at scale.
This is why context engineering has become essential. By supplying curated inputs, domain-specific rules, and continuous feedback loops, it bridges the critical final mile where edge cases derail automation projects. A robust context layer includes three elements:
- Curated inputs — normalized vendor feeds, shared taxonomies, verified pricing history
- Domain rules — variant logic, compliance checks, cross brand mapping, and tacit or tribal knowledge captured from experts
- Feedback loops — the agent resolves routine cases, routes exceptions to experts, and learns from each correction
Results achieved in live deployments
When these context layers are in place, the difference is immediate and measurable. Error rates fall, onboarding accelerates, and commercial metrics begin to improve. The numbers below reflect outcomes from recent deployments in manufacturing and distribution environments.
| Key metric | Before context layer | After context layer |
|---|---|---|
| Catalog error rate | about thirty percent | below five percent |
| Product-manager time on data work | roughly forty percent of weekly hours | below ten percent |
| Onboarding time for a new vendor feed | three to four weeks | less than one day |
| Add-to-cart lift | n/a | plus twelve percent in the first quarter |
A practical roadmap
Ready to apply these ideas to your own catalog? The following roadmap outlines the sequence of steps we use to move from audit to continuous improvement, distilling hard-won lessons into an actionable blueprint.
-
Audit the catalog to surface error hot spots, attribute gaps, and stale vendor files.
-
Prioritize high impact rules, beginning with compliance attributes, high-margin products, and workflows that depend on tacit or tribal expertise.
-
Prototype an agent workflow that ingests curated data, applies the rules, and flags only genuine exceptions.
-
Implement a feedback loop: review flagged exceptions, capture expert corrections, and feed those insights back into the rule set and prompts so the agent improves each cycle.
-
Measure outcomes in conversion lift, support burden, and hours saved, then refine both rules and model context in the next release.
Context rich AI pipelines transform raw product data from a perpetual cleanup chore into a strategic growth asset. By pairing curated inputs with AI agents and expert feedback, organizations compress weeks of catalog work into hours, release teams for higher-value analysis, and unlock measurable revenue lift. Now is the time to place context at the center of your product data strategy and convert noise into competitive advantage.